




競馬予想モデルを作成してみたく、機械学習用のデータをNetkeibaさん(https://www.netkeiba.com/)からスクレイピングさせて頂きました。
※学習初学者の勉強のアウトプットですので、もしコードや解釈に間違い等あればご指摘頂けますと幸いです。
メモも兼ねて、各コードなるべく詳しく説明をつけるようにしています。
Contents
スクレイピングの前に
スクレイピングに取り掛かる前に、まずは利用規約を一読しました。
スクレイピングNGという表現はなく、またデータも私的利用であれば大丈夫そうです。サイトによっては明確にスクレイピングNGとしているサイトもありますので、この点要注意です。
スクレイピングのコード
では、スクレイピングしたコードを記載していきます。
2015-2022年を訓練データ、2023年をテストデータとしたく、9年分のデータをスクレイピングしました。一気にデータ取得するとかなりの時間を要しますので、以下コード内では3年分(2015-2017年)のデータをひとまず取得しました。年のリストを変更し、3回実施致ました。3年分のデータ取得で4時間半ほどかかりました。
#Netkeibaからスクレイピングを行う
#必要なモジュールのインポート
import requests
from bs4 import BeautifulSoup
import urllib
import pandas as pd
import csv
import re
#2015-2017年のデータを取る
#解析するURLを入れるリストを作成し、URLを保存していく
urls = []
for y in ["2015","2016","2017"]:#年の指定
for l in ["01","02","03","04","05","06","07","08","09","10"]:#競馬場番号
for h in ["01","02","03","04","05","06"]:#開催回数
for d in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#開催日
for r in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#レース番号
urls.append(f"https://db.netkeiba.com/race/{y}{l}{h}{d}{r}/")
#スクレイピングしたデータを格納するための空のデータフレームを作っておく
result_df = pd.DataFrame()
#中にはデータが存在しないURLもあるため、try/exceptにてエラーが出た場合処理を飛ばすようにする
for url in urls:
try:
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser") #textだと文字化けするので、html.contentに変更する
#テーブル以外の要素の抽出を行う
race_title = soup.find(class_="racedata fc").find("h1")#レース名
ground = soup.find(class_="racedata fc").find("span").contents[0][0]#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
turn = soup.find(class_="racedata fc").find("span").contents[0][1]#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
distance = re.findall(r'\d{4}', soup.find(class_="racedata fc").find("span").contents[0])[0]#距離 正規表現で数字4桁を探す
weather = re.findall(r'天候\s*:\s*([^\/]+)', soup.find(class_="racedata fc").find("span").contents[0].replace("\xa0",""))[0]#天候
ground_condition = re.findall(r'良|稍重|重|不良', soup.find(class_="racedata fc").find("span").contents[0])[0]#馬場状況
year = re.findall(r'(\d{4})',soup.find(class_="smalltxt").contents[0])[0]#開催年
date = re.findall(r'(\d{1,2}月\d{1,2}日)',soup.find(class_="smalltxt").contents[0])[0]#開催日
location = re.findall(r'\d+回(..)',soup.find(class_="smalltxt").contents[0])[0]#場所
#テーブル要素の抽出を行う
table = soup.find("table")
#テーブルデータの保存先を作る
#テーブルデータの最初のtr(ヘッダー)を除く行をすべて解析、その中にあるtd要素を全てテキストで抽出し、かつテーブル以外の要素と組み合わせ、保存先に保存
table_data =[]
for row in table.find_all("tr")[1:]:
new_row_data = [year] + [date] + [location] + [race_title.text] + [ground] + [turn] + [distance] + [weather] + [ground_condition] + [cell.get_text(strip=True) for cell in row.find_all(['td'])]
table_data.append(new_row_data)
df = pd.DataFrame(table_data)
result_df = pd.concat([result_df, df], ignore_index=True)
except Exception as e:
pass
# CSVファイルとして保存
result_df.to_csv("horse_db_2015_2017.csv", encoding="utf-8-sig")解説
#Netkeibaからスクレイピングを行う
#必要なモジュールのインポート
import requests
from bs4 import BeautifulSoup
import urllib
import pandas as pd
import csv
import re
#2015-2017年のデータを取る
#解析するURLを入れるリストを作成し、URLを保存していく
urls = []
for y in ["2015","2016","2017"]:#年の指定
for l in ["01","02","03","04","05","06","07","08","09","10"]:#競馬場番号
for h in ["01","02","03","04","05","06"]:#開催回数
for d in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#開催日
for r in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#レース番号
urls.append(f"https://db.netkeiba.com/race/{y}{l}{h}{d}{r}/")まず、必要なライブラリをインポートし、その後解析するURLを取得してappendでリスト(urls)に保存していきます。
netkeibaのURLのロジックについては、こちらのサイトを大いに参考にさせて頂きました。ありがとうございます!
#スクレイピングしたデータを格納するための空のデータフレームを作っておく
result_df = pd.DataFrame()
#中にはデータが存在しないURLもあるため、try/exceptにてエラーが出た場合処理を飛ばすようにする
for url in urls:
try:
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser") #textだと文字化けするので、html.contentに変更する抽出した情報を保存するために、まずは空のデータフレームを準備しておきます。
次に、urlsの中に格納したURLを解析してHTMLの情報を読み込んで行きますが、中にはurl内にデータが存在しないものもあり、その場合エラーで実行が止まってしまいます。try/Exceptを入れてエラーがでた時の処理を飛ばします。
上記で読み込んだHTMLから該当する情報を抽出していきます。
黄色の部分、赤枠のtable部分に分けて抽出していきました。
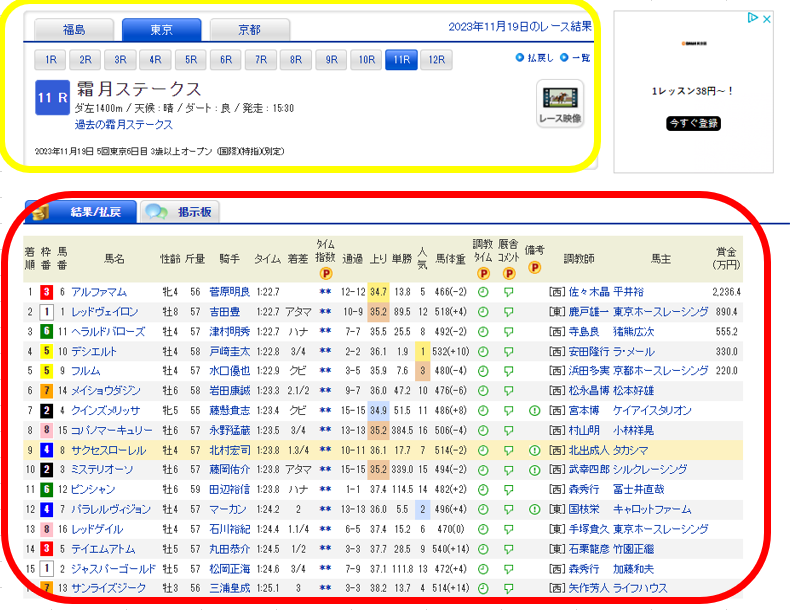
#テーブル以外の要素の抽出を行う
race_title = soup.find(class_="racedata fc").find("h1")#レース名
ground = soup.find(class_="racedata fc").find("span").contents[0][0]#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
turn = soup.find(class_="racedata fc").find("span").contents[0][1]#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
distance = re.findall(r'\d{4}', soup.find(class_="racedata fc").find("span").contents[0])[0]#距離 正規表現で数字4桁を探す
weather = re.findall(r'天候\s*:\s*([^\/]+)', soup.find(class_="racedata fc").find("span").contents[0].replace("\xa0",""))[0]#天候
ground_condition = re.findall(r'良|稍重|重|不良', soup.find(class_="racedata fc").find("span").contents[0])[0]#馬場状況
year = re.findall(r'(\d{4})',soup.find(class_="smalltxt").contents[0])[0]#開催年
date = re.findall(r'(\d{1,2}月\d{1,2}日)',soup.find(class_="smalltxt").contents[0])[0]#開催日
location = re.findall(r'\d+回(..)',soup.find(class_="smalltxt").contents[0])[0]#場所まず、黄色枠部分の情報で分析に使うであろう情報を抽出し、各変数に格納していきます。
久しぶりの正規表現に苦労しました。適宜Chat GPT先生にお助け頂きました。
#テーブルデータの保存先を作る
#テーブルデータの最初のtr(ヘッダー)を除く行をすべて解析、その中にあるtd要素を全てテキストで抽出し、かつテーブル以外の要素と組み合わせ、保存先に保存
table_data =[]
for row in table.find_all("tr")[1:]:
new_row_data = [year] + [date] + [location] + [race_title.text] + [ground] + [turn] + [distance] + [weather] + [ground_condition] + [cell.get_text(strip=True) for cell in row.find_all(['td'])]
table_data.append(new_row_data)
df = pd.DataFrame(table_data)
result_df = pd.concat([result_df, df], ignore_index=True)
except Exception as e:
pass次に、赤枠のtable部分の情報を抽出していきます。for row in table.find_all("tr")[1:]:とすることにより、カラム名を除外することができます。
かつ上述で抽出した黄色枠部分の情報を加えて、データフレームを作ります。
# CSVファイルとして保存
result_df.to_csv("horse_db_2015_2017.csv", encoding="utf-8-sig")最後に抽出した情報をcsvに保存し、試しにダウンロードして中身を確認!バッチリです!
3年分抽出で4時間半ほどかかりましたが、ファイルが出来上がった時にはPythonのすごさを改めて感じました(涙)

からスクレイピングさせて頂きました。 ※学習初学者の勉強のアウトプットです){kind=link}