




こちらの記事では、自然言語処理についてまとめています。
自然言語処理とは?
自然言語とは、日本語や英語のような自然発生的に生まれた言語です。
日常的に使用している自然言語について、言葉が持つ意味を解析し処理します。活用事例としては、チャットボット、音声認識AI、文字認識(手書き文字をカメラが認識し文字データへと変換する技術)、検索エンジン、翻訳、感情分析、文章要約などがあります。
文章の意味を機械に理解させるには、単語分割を行う必要があります。手法は主に2つあります。
1.形態素解析
形態素とは意味を持つ最小の言語単位で、単語は一つ以上の形態素を持ちます。
形態素解析は、辞書を利用して形態素に分割し、さらに形態素毎に品詞などの情報を付与することです。
2.Ngram
N文字毎、N単語毎に文章を切り分ける手法です。1文字ないし1単語で切り分けたものをユニグラム、2文字(単語)毎をバイグラム、3文字(単語)
毎をトリグラムと呼びます。Ngramは形態素解析のように辞書や文法的な解釈が不要なため言語に関係なく使用可能ですが、ノイズが大きくなるというデメリットがあります。
自然言語処理の実装
形態素解析を行う際は形態素解析ツールを使用します。日本語の形態素解析ツールとしてが、MeCabやjanome等があります。
今回はjanomeを使って形態素解析を行い、単語の頻出数を棒グラフとwordcloudで可視化してみたいと思います。
#必要なライブラリをインポートする
import re
import unicodedata
from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from collections import Counter
from matplotlib import font_manager
from wordcloud import WordCloud
with open("sample.txt", encoding="utf=8") as f:
text = f.read().replace('\n', '').replace(' ','')
#text内に格納された文章の中で不要な文字や記号を削除する
text = re.sub(":","", text)
#janomeで形態素解析を行う
t = Tokenizer()
tokenized_text = t.tokenize(text)
#格納する空リストを作成する
word_list = []
for token in tokenized_text:
tokeneized_word = token.surface # 形態素解析
hinshi = token.part_of_speech.split(",")[0]
if (hinshi == "名詞") or (hinshi == "動詞"):
word_list.append(tokeneized_word)
#Top20の頻出単語を棒グラフで可視化してみる
# 単語の出現頻度をカウント
word_freq = Counter(word_list)
# 上位20件の単語とその頻度を取得
top_words = word_freq.most_common(20)
# 単語と頻度をそれぞれリストに分割
words, freqs = zip(*top_words)
# 日本語フォントの指定
jp_font_path = 'BIZ-UDGOTHICB.TTC'
jp_prop = font_manager.FontProperties(fname=jp_font_path)
# 棒グラフの描画
plt.figure(figsize=(10, 6))
plt.bar(words, freqs, color='skyblue')
plt.xlabel('Words', fontproperties=jp_prop) # X軸ラベルに日本語フォントを指定
plt.ylabel('Frequency')
plt.title('Top 20 Words by Frequency')
plt.xticks(rotation=45, ha='right', fontproperties=jp_prop) # X軸のラベルを回転させて読みやすくし、日本語フォントを指定
plt.tight_layout()
plt.show()
#WordListに含まれる言葉を空白で区切って一つの文字列にする
words_wakachi = " ".join(word_list)
print(words_wakachi)
#日本語のフォントを指定する
font = 'BIZ-UDGOTHICB.TTC'
#意味のない言葉を除外する
stopWords = ["さ","する","これ","あり","こと","でき","し","い","ため"]
#WordCloudを表示する
word_cloud = WordCloud(font_path=font, width=800, height=400,
stopwords=set(stopWords),min_font_size=5,
collocations=False, background_color='white',
max_words=400).generate(words_wakachi)
figure = plt.figure(figsize=(15,10))
plt.imshow(word_cloud)
plt.tick_params(labelbottom=False, labelleft=False)
plt.xticks([])
plt.yticks([])
plt.show()
ではブロック毎に見ていきたいと思います。
#必要なライブラリをインポートする
import re
import unicodedata
from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from collections import Counter
from matplotlib import font_manager
from wordcloud import WordCloud
with open("sample.txt", encoding="utf-8") as f:
text = f.read().replace('\n', '').replace(' ','')
#text内に格納された文章の中で不要な文字や記号を削除する
text = re.sub(":","", text)
まず、必要なライブラリをインポートし、今回解析したいテキストが格納されているsample.txtを読み込み、改行・空白、そして不要な記号(今回は":"を取り除いています)を削除します。
#janomeで形態素解析を行う
t = Tokenizer()
tokenized_text = t.tokenize(text)
#格納する空リストを作成する
word_list = []
for token in tokenized_text:
tokeneized_word = token.surface # 形態素解析
hinshi = token.part_of_speech.split(",")[0]
if (hinshi == "名詞") or (hinshi == "動詞"):
word_list.append(tokeneized_word)まず、Tokenizer()を使用してjanomeのTokenizerオブジェクトを作成し、textを入れて形態素解析を行います。
for文を使って、トークンリスト内の各トークンに対して処理を行います。トークンを表示すると以下画像のようなものが表示されます。
token.surfaceで形態素解析した言葉が(以下で言う電子、ピアノ等)、token.part_of_speech.split(",")[0]で品詞が取り出せます。
今回は、名詞と動詞を抽出し、予め準備しておいた空のリストにappendで格納します。

#Top20の頻出単語を棒グラフで可視化してみる
# 単語の出現頻度をカウント
word_freq = Counter(word_list)
# 上位20件の単語とその頻度を取得
top_words = word_freq.most_common(20)
# 単語と頻度をそれぞれリストに分割
words, freqs = zip(*top_words)
# 日本語フォントの指定
jp_font_path = 'BIZ-UDGOTHICB.TTC'
jp_prop = font_manager.FontProperties(fname=jp_font_path)
# 棒グラフの描画
plt.figure(figsize=(10, 6))
plt.bar(words, freqs, color='skyblue')
plt.xlabel('Words', fontproperties=jp_prop) # X軸ラベルに日本語フォントを指定
plt.ylabel('Frequency')
plt.title('Top 20 Words by Frequency')
plt.xticks(rotation=45, ha='right', fontproperties=jp_prop) # X軸のラベルを回転させて読みやすくし、日本語フォントを指定
plt.tight_layout()
plt.show()Counter(word_list)でword_list内の単語頻出頻度をカウントします。これにより各単語の出現回数が辞書の形で返されます。
word_freq.most_common(20)で出現頻度の高い上位20件の単語とその頻度を取得します。
zip(*top_words)で上位単語と頻度をそれぞれwordsとfreqsリストに分割します。単語と頻度を別々のリストとして取得できます。
今回は日本語フォントをグラフに適用させたいので、日本語フォントのファイルパスを指定し、FontPropertiesオブジェクトを作成しておきます。Matplotlibで描画すると以下のようなグラフが表示されます。
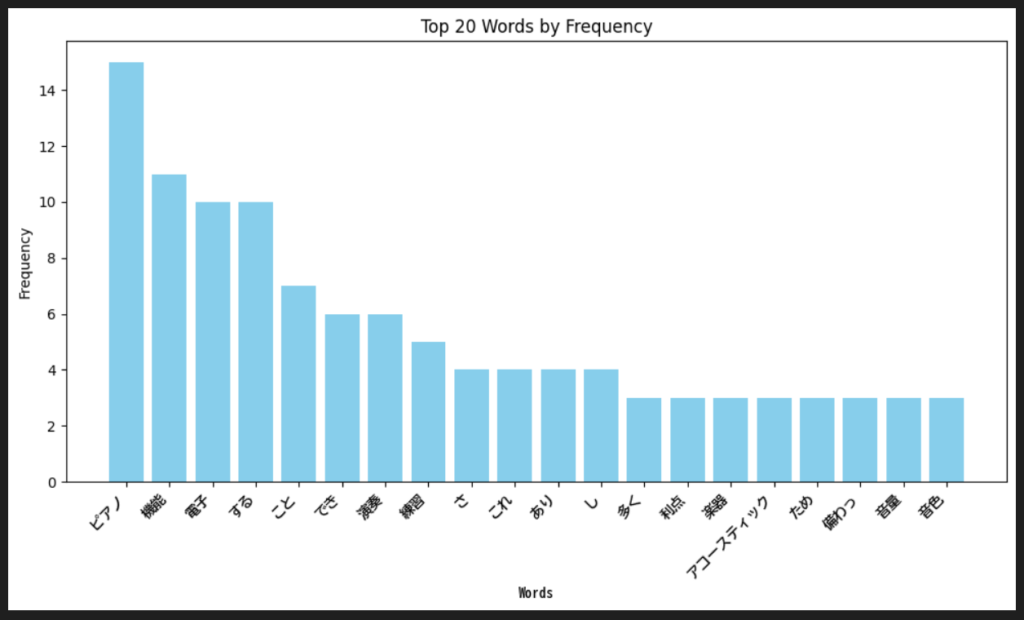
#WordListに含まれる言葉を空白で区切って一つの文字列にする
words_wakachi = " ".join(word_list)
print(words_wakachi)
#日本語のフォントを指定する
font = 'BIZ-UDGOTHICB.TTC'
#意味のない言葉を除外する
stopWords = ["さ","する","これ","あり","こと","でき","し","い","ため"]
#WordCloudを表示する
word_cloud = WordCloud(font_path=font, width=800, height=400,
stopwords=set(stopWords),min_font_size=5,
collocations=False, background_color='white',
max_words=400).generate(words_wakachi)
figure = plt.figure(figsize=(15,10))
plt.imshow(word_cloud)
plt.tick_params(labelbottom=False, labelleft=False)
plt.xticks([])
plt.yticks([])
plt.show()まず、word_listを空白で区切り一つの文字列にします。

もともとは↑でしたが、加工後は↓のようになりました。

日本語フォントを指定し、stopWordsで意味のない言葉を指定しておきます。
WordCloudでWordCloudを表示するための準備を行い、Matplotlibで描画をすると、以下のようになります。


{kind=link}