




こんにちは、Haruです! 育休中にPythonというプログラミング言語を勉強中です。
元々は仕事の業務効率化で使いたく(時短なので残業せずに帰りたいため)Pythonを勉強し始めたのですが、日常生活のちょっとした情報収集にも使えました。
今回は保活での活用法を紹介したいと思います。

そろそろ保活の時期。上の子の転園も検討しようかな。
私の住んでる◯区にけっこう保育園とこども園あるけど、市のHPからリンク全部クリックしてページ遷移して情報確認するのめんどくさーい!!
こういう時こそスクレイピングですよ。
私でコードを書いて実行しなさい。1発でCSVファイルにして出力してあげますよ。
まじですか!!あなたは神ですか!!
というわけでいってみましょう!
スクレイピングとは?
スクレイピングは「こする」「かき集める」といった意味を持つ「Scrape」に由来する用語で、Webやデータベースを広く探って「データを抽出する手法」のことです。
HaruはPythonというプログラミング言語の「Beautiful Soup」というライブラリを使って今回スクレイピングをして保活情報収集を効率的に行いました。
Beautiful SoupとはHTMLファイルやXMLファイルからデータを抽出するためのPythonライブラリです。
robots.txtの確認
スクレイピングをするにあたって必ずやらなければいけないのが、スクレイピングするサイトのrobots.txtの確認です。
robots.txtとは、サイトを巡回するクローラーの動作をコントロールするために記述されたテキストファイルのことで、スクレイピングをしたいサイトのURLの後ろに/robots.txtをつけると確認することができます。
例えば以前仕事で担当していたフィリピン、某サイトはこんな感じになっています。
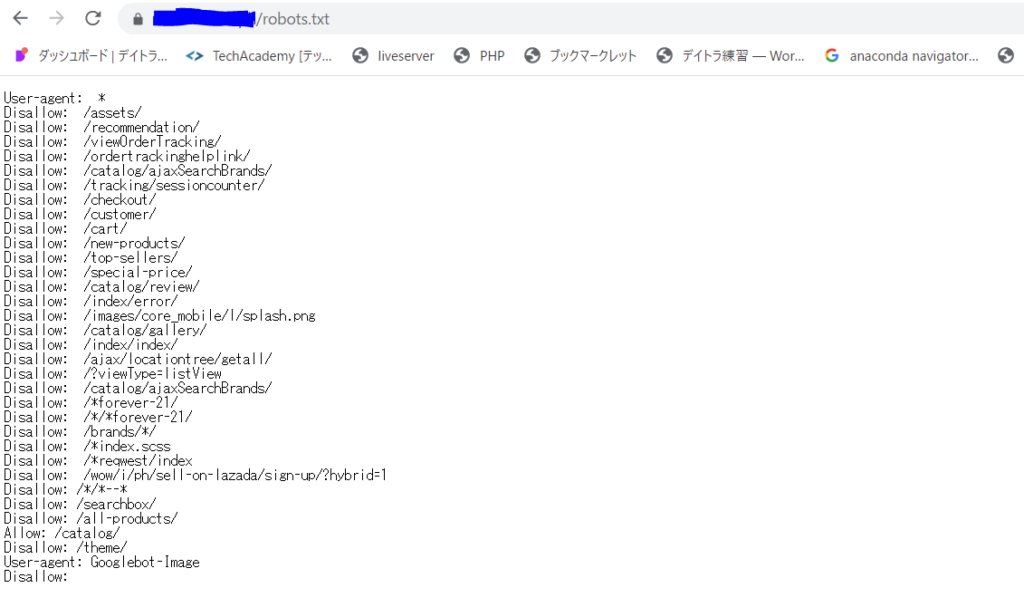
Disallowがたくさんです。このサイト内のこのURLではスクレイピングはしてくれるな!!という指定がずらっと記載されています。
そしてHaruが今回スクレイピングしたいサイトのrobots.txtを見てみると、以下のようでした。
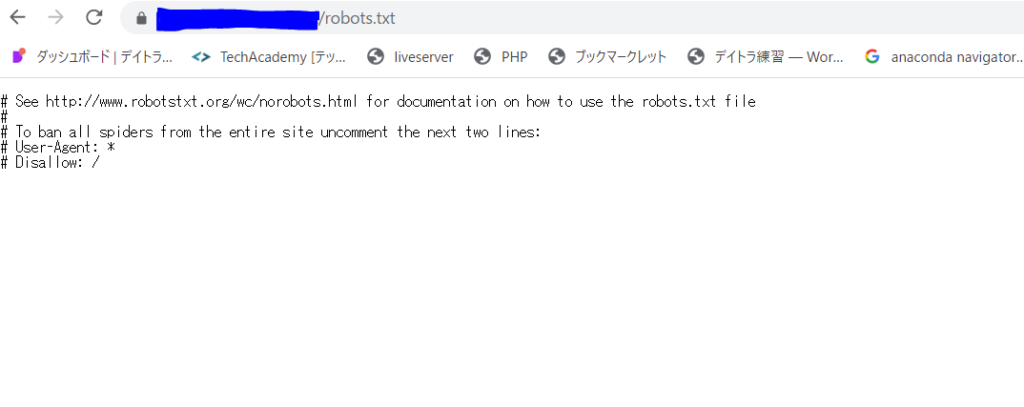
ふぬ、特に記載はなくスクレイピングを拒否されているURLはなさそう。では有難く情報収集させて頂きましょう。
書いたコード
#必要なライブラリのインポート
import requests
from bs4 import BeautifulSoup
import urllib
import time
import pandas as pd
# webページを取得して解析する
load_url = "ここに解析したいURLを入れました"
html = requests.get(load_url)
soup = BeautifulSoup(html.text, "html.parser")
#取得したい要素の空リストを作成する
links = []
names = []
divisions = []
categories = []
places = []
tels = []
# 全部の区のclassで検索し、その中の全ての"a"タグを検索して表示する
# 施設名、リンクを絶対URLで表示する
for facilities in soup.find_all(class_="facilities"):
for title in facilities.find_all("a"):
names.append(title.string)
links.append(urllib.parse.urljoin(load_url, title.get("href")))
# 地域, 分類, 所在地, 電話情報をtdタグ、class名より検索し、空リストに格納していく
for division, category, place, tel in zip(facilities.find_all('td', class_="division"),
facilities.find_all('td', class_="category"),
facilities.find_all('td', class_="place"),
facilities.find_all('td', class_="tel")):
divisions.append(division.string)
categories.append(category.string)
places.append(place.string)
tels.append(tel.string)
# DataFrameに保存
df = pd.DataFrame({"Name":names, "Division":divisions, "Category":categories, "Place":places, "Tel":tels, "Link":links})
# テーブルを指定
find_conditions = [
{"class":"basicInfo wide"},
{"class":"basicInfo narrow"},
{"class":"detailedInfo"}
]
for ix, link_url in enumerate(df["Link"]):
html = requests.get(link_url)
soup = BeautifulSoup(html.text, "html.parser")
# 1回アクセスしたので1秒待つ
time.sleep(1)
# テーブル内の要素を取得する
for condition in find_conditions:
table = soup.find("table", condition)
try:
for column, value in zip(table.find_all("th"), table.find_all("td")):
if not column.text in df.columns:
df[column.text] = ''
df.at[ix, column.text] = value.text
except AttributeError:
pass
# 整形する
for column in df.columns:
df[column] = df[column].str.replace(" ", "")
df[column] = df[column].str.replace("\t", "")
df[column] = df[column].str.replace("\n", "")
# CSVファイルに出力する
df.to_csv("kindergartens.csv", encoding="utf-8-sig")出力結果
上のコードを書いて実行すると、あら素敵!一覧リストになって出力されました!(個人情報保護のため青でマスキングしています)
私はこのファイルで区・地域及び保育標準時間欄でソートをして、候補園を絞り込みました。

まとめ
本当にPython便利です!
一回コードを書いてしまえば、大体パターンは一緒なので少し修正するだけで使いまわすことができます。
せっかく勉強したPython。仕事だけでなく日常生活にもドンドン使っていきたいと思います。

Pythonを勉強し始めたのですが、日常生活){kind=link}