



ハイパーパラメータを調整してくれるOptunaというライブラリを使ってみました。こちらのサイトを元に、備忘録としてコードの説明をつけました。(大いに参考にさせて頂きました。ありがとうございます!)
※学習初学者の勉強のアウトプットですので、もしコードや解釈に間違い等あればご指摘頂けますと幸いです。
メモも兼ねて、各コードなるべく詳しく説明をつけるようにしています。
Contents
Optunaとは?
そもそもハイパーパラメータとは、機械学習アルゴリズムの挙動を制限するパラメータのことですが、ハイパーパラメータの数はとても多く、マニュアルで調整を行うとかなりの時間を要します。
そこで使用するのがOptunaです。Optunaはハイパーパラメータの最適化を自動で行ってくれるライブラリで、優れた性能を発揮するハイパーパラメータの値を自動的に発見してくれる、とても便利なものです。
Optunaの実装
今回はsklearnの乳がんのデータセットとOptunaでハイパーパラメータを調整してみようと思います。
#必要なモジュールをインポートする
import optuna
import pandas as pd
import sklearn.svm
from sklearn import linear_model
from sklearn import ensemble
from sklearn import datasets
from sklearn import model_selection
from sklearn import metrics
#乳がんのデータセットを取得し、中身を確認する
cancer = datasets.load_breast_cancer()
#Xに特徴量を格納する
X = cancer.data
#yにtargetを格納する
y = cancer.target
# 目的関数の設定
def objective(trial):
#ハイパーパラメータの集合を定義する
##分類モデルの集合
classifier_name = trial.suggest_categorical("classifier",
["LogReg",
"SVC",
"RandomForest"
]
)
##分類モデルごとのハイパーパラメータの集合
###ロジスティック回帰
if classifier_name == 'LogReg':
logreg_c = trial.suggest_float("logreg_c",
1e-10, 1e10,
log=True
)
classifier_obj = linear_model.LogisticRegression(C=logreg_c)
###サポートベクターマシン
elif classifier_name == "SVC":
svc_c = trial.suggest_float("svc_c",
1e-10, 1e10,
log=True
)
classifier_obj = sklearn.svm.SVC(C=svc_c,
gamma="auto")
###ランダムフォレスト
else:
rf_n_estimators = trial.suggest_int("rf_n_estimators",
10, 1000
)
rf_max_depth = trial.suggest_int("rf_max_depth",
2, 50,
log=True
)
classifier_obj = ensemble.RandomForestClassifier(
max_depth=rf_max_depth,
n_estimators=rf_n_estimators
)
#評価を行う
score = model_selection.cross_val_score(classifier_obj,
X,
y,
n_jobs=-1,
cv=10
)
#結果の平均値
accuracy = score.mean()
return accuracy
#目的関数の最適化を実行する
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
# 上のstudyで得られた最高値とパラメータを表示する
print(f"The best value is : \n {study.best_value}")
print(f"The best parameters are : \n {study.best_params}")解説
#乳がんのデータセットを取得し、中身を確認する
cancer = datasets.load_breast_cancer()
#Xに特徴量を格納する
X = cancer.data
#yにtargetを格納する
y = cancer.target必要なライブラリをインポートした後、乳がんのデータセットを読み込みます。
cancer.dataで30個の特徴量を全てXに格納、cancer.targetでyにラベルを格納します。念のため中身を確認します。
以下、Xです。格納できていますね。
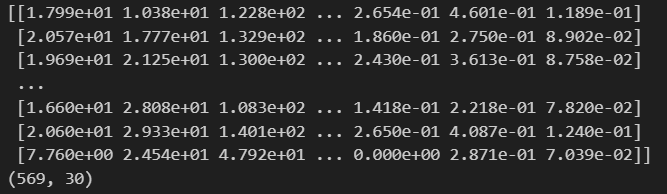
こちら、yになります。

# 目的関数の設定
def objective(trial):
#ハイパーパラメータの集合を定義する
##分類モデルの集合
classifier_name = trial.suggest_categorical("classifier",
["LogReg",
"SVC",
"RandomForest"
]
)今回の例では、分類モデルの中で最適なパラメータを探していきます。
カテゴリカルなパラメータとして、ロジスティック回帰/SVC/ランダムフォレストを指定しています。Optunaを使用し、これらの中から最適なパラメータを選択します。カテゴリカルなパラメータを定義する時はtrial.suggest_categorical()メソッドを使用します。
##分類モデルごとのハイパーパラメータの集合
###ロジスティック回帰
if classifier_name == 'LogReg':
logreg_c = trial.suggest_float("logreg_c",
1e-10, 1e10,
log=True
)
classifier_obj = linear_model.LogisticRegression(C=logreg_c)
分類モデル ロジスティック回帰の場合のパラメータを定義していきます。
ロジスティック回帰モデルにおいては正則化のパラメータ(C)である"logreg_c"が重要で、今回はこの値の最適値を見つけていきます。
正則化パラメータCを1e-10, 1e10の範囲内で制御し、小さな値から始まり徐々に大きな値に変化させていくようにしています。
log=Tureで指数的なスケールで提案されます。
###サポートベクターマシン
elif classifier_name == "SVC":
svc_c = trial.suggest_float("svc_c",
1e-10, 1e10,
log=True
)
classifier_obj = sklearn.svm.SVC(C=svc_c,
gamma="auto")分類モデル SVMの場合のパラメータを定義していきます。
SVMモデルの正則化のパラメータ(C)である"svc_c"を定義しています。
こちらも、正則化パラメータCを1e-10, 1e10の範囲内で制御し、小さな値から始まり徐々に大きな値に変化させていくようにしています。
log=Tureで指数的なスケールで提案されます。
###ランダムフォレスト
else:
rf_n_estimators = trial.suggest_int("rf_n_estimators",
10, 1000
)
rf_max_depth = trial.suggest_int("rf_max_depth",
2, 50,
log=True
)
classifier_obj = ensemble.RandomForestClassifier(
max_depth=rf_max_depth,
n_estimators=rf_n_estimators
)分類モデル ランダムフォレストのパラメータを定義していきます。
"rf_n_estimators"はランダムフォレストの決定木の数を指定するハイパーパラメータです。trial.suggest_int()を使用して、与えられた範囲内で整数値が探索されます。この例では、10から1000までの間で探索されます。
rf_max_depth これは、ランダムフォレストの各決定木の最大深度を指定するハイパーパラメータです。trial.suggest_intを使用して、与えられた範囲内で整数値が探索されます。log=Trueという指定により、対数スケールで値が探索されます。
#評価を行う
score = model_selection.cross_val_score(classifier_obj,
X,
y,
n_jobs=-1,
cv=10
)
#結果の平均値
accuracy = score.mean()
return accuracymodel_selection.cross_val_score()関数は、指定された分類器(classifier_obj)とデータ(X,y)に対して、交差検証を実行します。
ここでは、cvパラメータで指定された分割数(ここでは10)でデータが分割され、各分割に対してモデルがトレーニングされ、テストされます。n_jobs=-1は、可能な場合に全てのCPUコアを使用して並列化するためのオプションです。
score.mean()で交差検証で得られたスコアの平均値を計算します。これにより、モデルの平均的な性能を評価できます。
最後にaccuracyを返します。この精度は、交差検証を通じて得られた平均的なモデルの性能を示します。
#目的関数の最適化を実行する
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
# 上のstudyで得られた最高値とパラメータを表示する
print(f"The best value is : \n {study.best_value}")
print(f"The best parameters are : \n {study.best_params}")optuna.create_study(direction="maximize")は、Optunaの研究を作成します。最適化の方向はとしてmaximizeにて目的関数が最大化することを指定しています。
study.optimize(objective, n_trials=100)は目的関数objectiveを最適化します。ここでは、n_trialsパラメータで指定された数の試行を行います。
今回は100を指定していますので、100回試行されています。
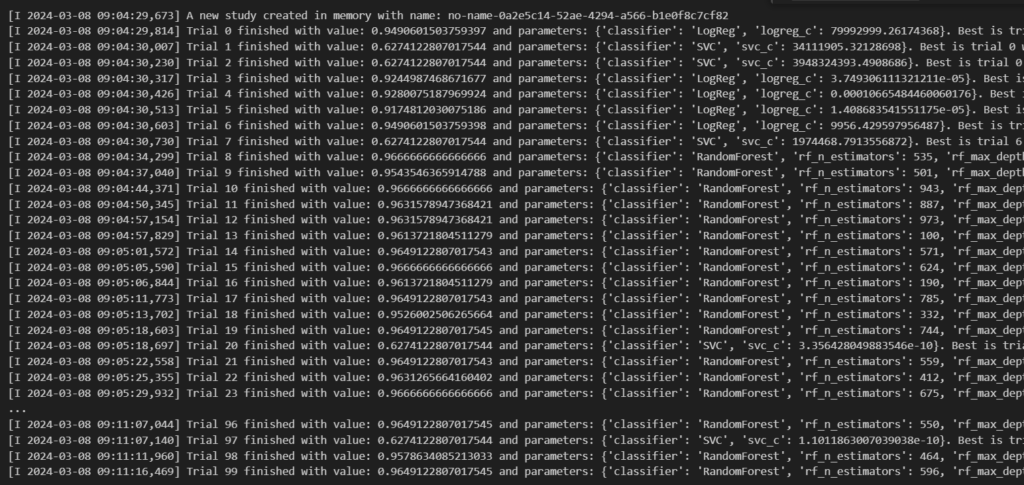
study.best_valueでは、最適化中に見つかった最高値を示します。また、study.best_paramsで最良のパラメータの組み合わせを表示させることができます。以下のようになりました。


 ※){kind=link}