



外れ値の処理についてまとめています。
Contents
外れ値とは?
外れ値とは、他のデータと著しく乖離したデータのことを指します。
データ内に外れ値が混在していると、分析結果に影響を及ぼしたり、機械学習モデルの学習過程で影響がでてしまい学習が進みにくくなる、などの影響が出てしまいます。
外れ値の検知方法について
外れ値の検知方法について、可視化、LOF(Local Outlier Factor )、Isolation Forestの3つの手法について紹介します。
可視化による外れ値の検知
外れ値があるかどうか、まず可視化して確かめてみるのがよいです。
#必要なライブラリをインポートする
import pandas as pd
import numpy as np
import openpyxl
import matplotlib.pyplot as plt
import seaborn as sns
#Excelを読み込む
data = pd.read_excel("sampledata_outlier.xlsx")
#タイムを箱ひげ図にて可視化する
sns.boxplot(y=data["time"])
#joinplotで散布図とヒストグラムを描画する
#今回は、x軸にtime、y軸にdistanceとして可視化をしてみる
x_data = data["time"]
y_data = data["distance"]
sns.jointplot(x=x_data, y=y_data, data=data)可視化の手法について、箱ひげ図、散布図+ヒストグラムでの描画を行ってみます。
#必要なライブラリをインポートする
import pandas as pd
import numpy as np
import openpyxl
import matplotlib.pyplot as plt
import seaborn as sns
#Excelを読み込む
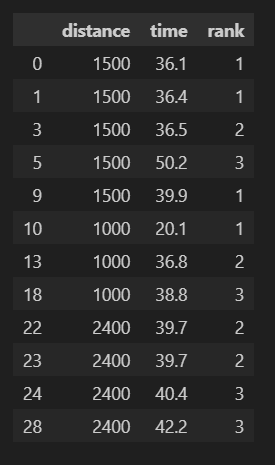
data = pd.read_excel("sampledata_outlier.xlsx")まず、必要なライブラリをインポートし、データを読み込みます。今回は以下のようなサンプルデータを準備しました。3カラムのデータです。
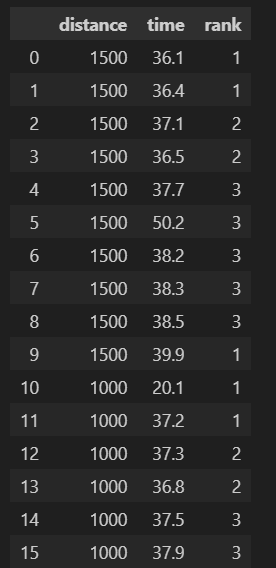
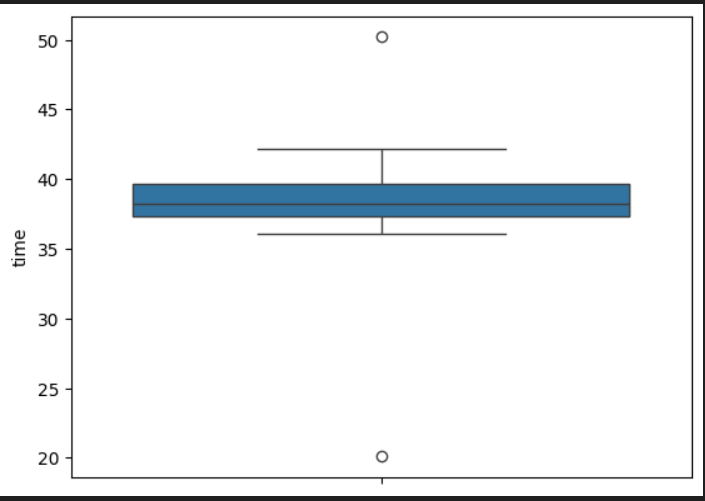
#timeカラムを箱ひげ図にて可視化する
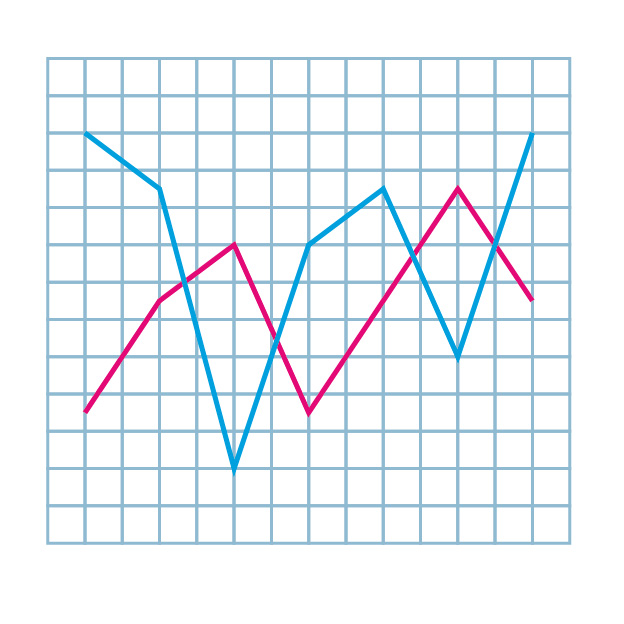
sns.boxplot(y=data["time"])timeカラムを箱ひげ図で描画してみます。〇が外れ値です。
#joinplotで散布図とヒストグラムを描画する
#今回は、x軸にtime、y軸にdistanceとして可視化をしてみる
x_data = data["time"]
y_data = data["distance"]
sns.jointplot(x=x_data, y=y_data, data=data)データが二次元の場合は、散布図とヒストグラムを同時に描画してくれるjointplotが使えます。
今回は、x軸にtime, y軸にdistanceを設定し可視化してみます。目視で確認すると、タイムに外れ値がありそうです。
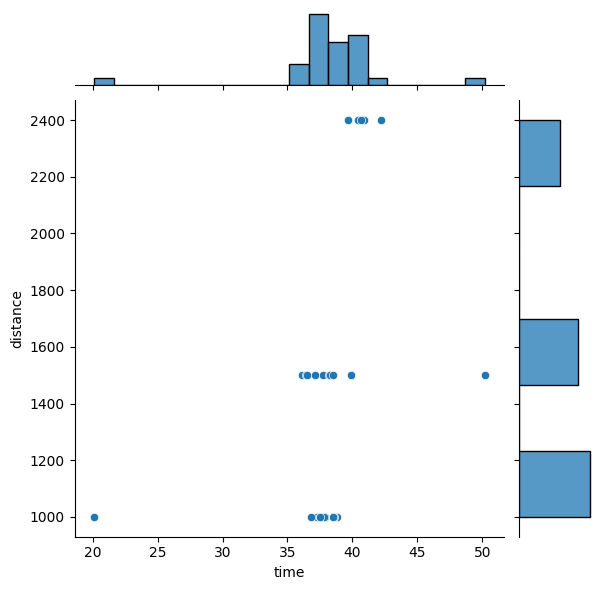
LOF(Local Outlier Factor )による外れ値の検知
LOFはデータの密度に基づいて外れ値を検知する方法です。LOFには、近くにデータ点が少ないのが外れ値であると考える、k個の近傍点を使ってデータの密度を推定する、密度が周囲と相対的に低い点を外れ値と判定する、という特徴があります。
Scikit-learnにて簡単に検知することができます。
#必要なライブラリをインポートする
import pandas as pd
import numpy as np
import openpyxl
from sklearn.neighbors import LocalOutlierFactor
#Excelを読み込む
data = pd.read_excel("sampledata_outlier.xlsx")
#LocalOutlierFactorでパラメータを指定し(何個の近傍点を使うか)、分類モデルを作成する
clf = LocalOutlierFactor(n_neighbors=3)
predictions= clf.fit_predict(data)
data[predictions == -1]可視化と同じデータを使って試してみます。
#必要なライブラリをインポートする
import pandas as pd
import numpy as np
import openpyxl
from sklearn.neighbors import LocalOutlierFactor
#Excelを読み込む
data = pd.read_excel("sampledata_outlier.xlsx")必要なライブラリをインポートしてExcelを読み込みます。
#LocalOutlierFactorでパラメータを指定し(何個の近傍点を使うか)、分類モデルを作成する
clf = LocalOutlierFactor(n_neighbors=3)
predictions= clf.fit_predict(data)
data[predictions == -1]LocalOutlierFactor関数で、何個の近傍点(n_neighbors)を使うかパラメータ指定をして分類モデルを作成します。この例では3で実行しました。
fit_predictでデータを学習させて外れ値を検出します。
predictionの返り値は以下のようになります。外れ値とみなしたデータ行では値が-1に、正常なものは1が返ってきます。

data[predictions == -1]で、外れ値と判定された行を取得できます。
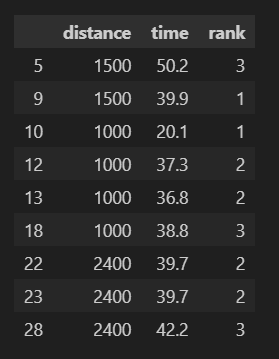
Isolation Forestによる外れ値の検知
Isolation Forestは、計算が複雑ではなく省メモリ、大規模なデータでも計算しやすい、というメリットがあります。
特定のデータ項目でランダムにデータを分割→別のデータ項目でランダムにデータ分割→これ以上分割できないデータを2回の分割で作成できたのでこれをdepth=2として記録→これらを繰り返し各点の深さの平均を計算するといったアルゴリズムで外れ値を検出します。
外れ値ほど深さの平均が小さい値となるため、深さが小さいデータを外れ値として判定することができます。
#必要なライブラリをインポートする
import pandas as pd
import numpy as np
import openpyxl
from sklearn.ensemble import IsolationForest
#Excelを読み込む
data = pd.read_excel("sampledata_outlier.xlsx")
#Isolation Forestで外れ値を検知する
clf = IsolationForest()
clf.fit(data)
prediction = clf.predict(data)
data[prediction == -1]必要なライブラリをインポートしてExcelを読み込みます。
#Isolation Forestで外れ値を検知する
clf = IsolationForest()
clf.fit(data)
prediction = clf.predict(data)
data[prediction == -1]Isolation Forestモデルを作成し、元のデータに適合させ、predictメソッドを使用して外れ値を予測します。予測された値がpredictionに返ってきます。外れ値とみなしたデータ行では値が-1に、正常なものは1が返ってきます。
外れ値を表示させてみると、以下のようになります。

{kind=link}