




機械学習(教師あり学習 分類)のLightGBMを実装してみたいと思います。
※学習初学者の勉強のアウトプットですので、もしコードや解釈に間違い等あればご指摘頂けますと幸いです。
メモも兼ねて、各コードなるべく詳しく説明をつけるようにしています。
前提:教師あり学習 分類とは?
カテゴリ別に分けてあるデータを学習し、未知のデータのカテゴリを予測する手法です。
新商品をメールで案内する時に、顧客の過去の購買履歴を使用し購買見込みが高い人を予測、その人のみに特別なメールを送る、などの活用例があります。
分類は大まかに2項分類、多項分類に分けられます。
2項分類:YES/ NOのように、予測するカテゴリが2つの分類を指します。さらに線形分類・非線形分類に分けられます。
多項分類:分類するカテゴリが3つ以上の分類を指します。
分類の主な手法について
・ロジスティック回帰:
線形分離可能なデータの境界線を見つけ、データの分類を行う手法。境界が直線になるので、2項分類等カテゴリの少ないデータの分類に使用される。「回帰」とあるが分類の手法であることに注意。
・線形SVM(サポートベクターマシン):
データの境界線を見つけ、線形分類を行う手法。SVMはサポートベクトルというベクトルを用いて境界線を引きます。SVMは境界線が2カテゴリの最も離れた場所に引かれるので、ロジスティック回帰よりも一般化されやすく精度が高い傾向があります。
・非線形SVM(サポートベクターマシン):
線形SVMの”線形分離可能なデータ"しか分類できない、という欠点を補うために開発されたモデルです。
・決定木:
データの説明変数(要素)に注目し、説明変数内のある値を堺にデータを分割し、データの属するカテゴリを決定する手法。
それぞれの説明変数が目的変数にどの程度の影響を与えているのかを見ることができます。分割を繰り返して枝分かれしていくが、先に分割される条件に用いられる変数ほど、影響力が高いと言えます。線形分離できないデータは分類が難しい点が欠点。
・ランダムフォレスト:
決定木を複数作り、分類の結果を多数決で決める手法。アンサンブル学習の手法の一つ。
決定木では、全ての説明変数を使用していたが、ランダムフォレストでは少数の説明変数を用いてデータのカテゴリを決定します。
線形分離できない複雑なデータでも分類可能。
・k-NN:
k近似法とも呼ばれる。予測するデータと類似したデータを見つけ、多数決により分離結果を決める手法。
教師データから学習するのではなく、教師データを直接参照してラベルを予測するのが他の分類手法との違い。k-NNの特徴としては、学習コストが0である点、アルゴリズムが単純だが比較的精度が高い点、複雑な形の境界線も表現可能な点が挙げられます。欠点としては、分類器に指定する自然数kの個数を増やしすぎると、識別範囲の平均化が進み、予測精度が下がってしまう点、教師データや予測データの数が増えると低速なアルゴリズムになってしまう点が挙げられます。
・Light GBM:
決定木の勾配ブースティングアルゴリズムであるXGBoostが発表された2-3年後に発表された高速・高精度なアルゴリズムで、Kaggle等のコンペでも多用されているモデル。勾配ブースティングアルゴリズムは学習を繰り返すことで誤差を最小化し、精度を高めていきます。データ量によって計算量も増えますが、一つ一つの決定木の精度を落とさず、かつ高速に構築ができることが最大の特徴となっています。回帰モデルもサポートしています。
Light GBMの実装
今回はskleranのirisデータセットを使用して、Light GBMを実装していきます。
4つの特徴量(sepal length(cm): がく片の長さ/sepal width(cm): がく片の幅/petal length(cm): 花びらの長さ/petal width(cm): 花びらの幅)とラベル(0: setosa/1:versicolor/2:virginica)で構成されているデータセット(150件)です。
#必要なモジュールをインポートする
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import lightgbm as lgb
import optuna
from sklearn.metrics import accuracy_score
#アヤメのデータセットを取得し、中身を確認する
iris = datasets.load_iris()
#irisデータセットの全行と全列をXに格納する
X = iris.data
#yにtargetを格納する
y = iris.target
#train_data ,testデータに分割し、分割できているか確認
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.3, random_state=42)
print(f"train_X:{train_X.shape}")
print(f"test_X:{test_X.shape}")
print(f"train_y:{train_y.shape}")
print(f"test_y:{test_y.shape}")
# XGBoostで学習するためのデータ形式に変換する
lgb_train = lgb.Dataset(train_X, train_y)
lgb_valid = lgb.Dataset(test_X, test_y)
params = {
'objective': 'multiclass', # 多クラス分類
'num_class': 3, # クラスの数
'metric': 'multi_logloss' # 損失関数にmulti_loglossを使用
}
# LightGBMでモデル構築を行う
model = lgb.train(params, lgb_train)
print(f"parameters: {model.params}")
# test_xに対するモデルの評価を行う
y_pred = model.predict(test_X)
y_pred_index = np.argmax(y_pred, axis=1)
print(y_pred_index)
print(test_y)
#算出したy_pred_indexとtest_yの正答率を出す
print(metrics.accuracy_score(test_y, y_pred_index))
print(metrics.classification_report(test_y, y_pred_index))
#重要度をプロット
lgb.plot_importance(model, height=0.5, figsize=(4,4))解説
#アヤメのデータセットを取得し、中身を確認する
iris = datasets.load_iris()
#irisデータセットの全行と全列をXに格納する
X = iris.data
#yにtargetを格納する
y = iris.target必要なライブラリをインポートした後、irisのデータセットを読み込みます。
iris.dataで4つの特徴量を全てXに格納、iris.targetでyにラベルを格納します。念のため中身を確認します。
以下、Xです。格納できていますね。
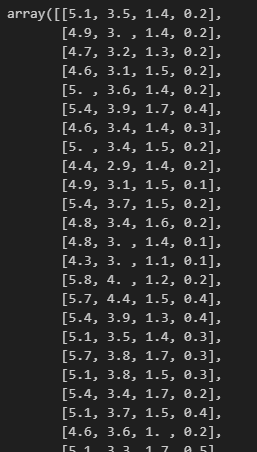
こちら、yになります。

#train_data ,testデータに分割し、分割できているか確認
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.3, random_state=42)
print(f"train_X:{train_X.shape}")
print(f"test_X:{test_X.shape}")
print(f"train_y:{train_y.shape}")
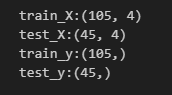
print(f"test_y:{test_y.shape}")trainデータ(0.7)とtestデータ(0.3)に分割し、分割できているかを念のため確認しておきます。
元々データセットは150件だったので、train_X: 105行×4列、test_X: 45行×4列、train_y: 105行×1列、test_y: 45行×1列となっていれば大丈夫です。念のため.shapeで確認しておきます。
# XGBoostで学習するためのデータ形式に変換する
lgb_train = lgb.Dataset(train_X, train_y)
lgb_valid = lgb.Dataset(test_X, test_y)
params = {
'objective': 'multiclass', # 多クラス分類
'num_class': 3, # クラスの数
'metric': 'multi_logloss' # 損失関数にmulti_loglossを使用
}まず、lgb.Datasetで、訓練データとテストデータをLightGBMが学習するためのデータ形式に変換します。これはLightGBMが効率的にデータを扱えるようにするための前処理です。
次にパラメータを設定します。次の項目で設定できるパラメータについてよく使うものをピックアップして説明します。
# LightGBMでモデル構築を行う
model = lgb.train(params, lgb_train)
print(f"parameters: {model.params}")
# test_xに対するモデルの評価を行う
y_pred = model.predict(test_X)
y_pred_index = np.argmax(y_pred, axis=1)
一つ上のコードで設定したパラメータを入れ、かつXGBoost形式に変換した訓練データを入れモデル構築します。(実際にモデルに入れて予測を行う時にこういった処理が必要の模様)
念のため、使用しているパラメータをmodel.paramsで確認しておきます。

y_predはモデルがテストデータに対して行った予測の結果を表します。具体的には、各テストデータに対する予測確率の配列が返ってきます。
今回のように3つのクラスの分類問題では、各行に3つの確率値が含まれる配列になります。
y_predを表示してみると、以下のような配列が表示されます。形状は(45,3)です。
クラス0に属する確率が約0.088%(8.81521864e-05)、クラス1に属する確率が約99.662%(9.96618565e-01)、クラス2に属する確率が約0.329%(3.29328326e-03)と読み解くことができます。
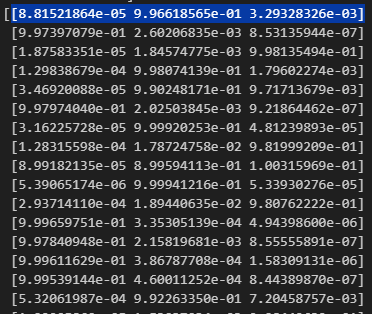
np.argmax(y_pred, axis=1)は、y_predの各行毎に最大値のインデックスを見つけるNumpy関数です。
上の青でマークした行を例にとると、クラス1になる確率が約99.662%(9.96618565e-01)となり、この行の中で最大となるので「1」が返されます。
print(y_pred_index)
print(test_y)LightGBMで予測したラベルと、テストデータのラベルを表示させ比べてみます。これだけでは正答率がわかりませんので、次のコードで正答率を出してみます。

#算出したy_pred_indexとtest_yの正答率を出す
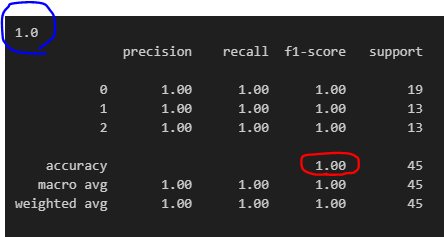
print(metrics.accuracy_score(test_y, y_pred_index))
print(metrics.classification_report(test_y, y_pred_index)).accuracy_scoreで出した正答率が青丸、テーブル形式のものがclassification_reportで出した正答率です。100%という結果です。
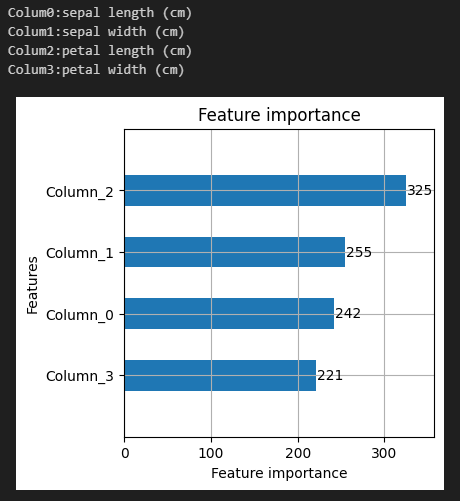
#重要度をプロット
lgb.plot_importance(model, height=0.5, figsize=(4,4))上記コードはLightGBMモデルの特徴量の重要度を可視化するためのものです。今回でいうと、Column2がモデルの性能に寄与していることがわかります。
LightGBMの主なパラメータ
上のコードでも今回、いくつかパラメータを設定しましたが主だったものを備忘録としてまとめました。
使用するモデルにより、適切なパラメータを設定する必要があります。
# objective(目的関数)パラメータ
params = {
#回帰
"objective":"regression",#デフォルト値、L2損失(平均二乗誤差、MSE)を最小化する回帰モデルを構築
"objective":"regression_l1",#L1損失(平均絶対誤差、MAE)を最小化する回帰モデルを構築
#二値分類
"objective":"binary",#ラベルは0 or 1
#多項分類
"objective":"multiclass",
}# metric(モデル構築の損失関数)のパラメータ、機械学習モデルの性能を評価するための基準や指標のこと
#機械学習モデルが与えられたタスクをどれだけうまく解決できているかを定量的に評価するために使用されます
params = {
#回帰
"metric":"mse",#デフォルト値、L2損失(平均二乗誤差、MSE)を最小化する回帰モデルを構築
"metric":"mae",#L1損失(平均絶対誤差、MAE)を最小化する回帰モデルを構築
#二値分類
"metric":"binary_logloss",#クロスエントロピー、分類モデルの性能評価の際に使われる
"metric":"binary_error",#正答率、正しく予測されたサンプルの割合を示し、分類モデルの全体的な予測精度を評価する
#多項分類
"metric":"multi_logloss",#多クラス交差エントロピー損失,予測が正しいクラスになる確率を最大化するように学習させる
"metric":"multi_error",#正解と異なるクラスに予測されたサンプルの割合
}#boosting、LightGBMなどの勾配ブースティングモデルのトレーニング中に使用されるパラメータです
params = {
"boosting":"gbdt",#デフォルト、従来の Gradient Boosting Decision Tree
"boosting":"rt",#ランダムフォレスト、訓練データからランダムに選択されたサンプルで多数の決定木をトレーニングし、それらの結果を平均して予測を行う
"boosting":"dart",#ドロップアウトを用いたアンサンブルアルゴリズム
"boosting":"goss",#勾配ベースの片側サンプリングアルゴリズム、情報の少ないサンプルを効果的に除外することで、トレーニングの効率を向上させることができる
}#num_class 多項分類の場合にクラスの数を設定することが推奨されている
params = {
#多項分類の場合
"num_class":3,
}#max_depth 決定木の深さ、デフォルトはfull treeまで学習してしまうので、何か値を入れておくのがよい
params = {
"max_depth":3,
}#learning_rate 学習の圧縮率、小さければ学習時間が必要となる
params = {
"learning_rate":"0.1"#デフォルト値は0.1
}#num_iterations モデルが学習する決定木の数
params = {
"num_iterations":"100"#デフォルト値は100
}
のLightGBMを実装してみたいと思います。 ※学習初学者の勉強のアウトプットですので、もしコードや解釈に間違い等あればご指摘頂けますと幸いです。メモも兼ねて、各コード){kind=link}